Some novelty logical clock + CRDT implement
Clock & p2p
Some implements of novelty logical clock + CRDTs for data consistency in distributed p2p applications.
Overview
The documents will discuss logical clock、crdt (Conflict-free Replicated Data Type)、and core data structures: Merkle-DAG of Merkle-CRDTs, Prolly-tree of Canvas, and HLC (hybrid logical clock).
So, if confused about those concepts, you can read the appendix reference for details.
Core concepts
Merkle-CRDTs
Background
Merkle-CRDTs come from Merkle-DAGs meet CRDTs paper by Protocol Labs and IPFS/FileCoin community. It was early used to sync KV data in a conflict-free way between IPFS cluster nodes. Now, ipfscluster still supports two consensus components, CRDT(default) and Raft.
As time passed, the followers utilized Merkle-CRDTs to keep consistency in distributed p2p database applications. Likes, orbitDB、defraDB of source network.
Major innovation
As we all know, the first logical clock is the Lamport clock, and the versioned clock and vector clock are as follows. In the Merkle-CRDTs context, the paper formalized defines Merkle-Clocks and proves it contains casualty ordering and other features of logical logic.
The Merkle-DAG is built by merging other DAGs in other replicas. New events are added as new root nodes (parents to the existing ones). Note that the Merkle-Clock may have several roots at a given time. Thus, Merkle-DAGs are not only ever-growing but also tend to be deep and thin.
pros and cons
PROS :
- Merkle-Clocks decouple the causality information from the number of replicas. vs. to vector clock.
- Merkle DAG is content-addressed and self-authenticating, so can tolerate dropped messages and network-disturbed.
CONS
- Ever-growing DAG-Size, Very large DAGs, and initial slow syncs
- Merkle-Clock sorting and merge may be a costly operation.
So when thinking about adopting Merkle-CRDTs, users should consider whether Merkle-CRDTs are the best approach in terms of:
- i) Node count vs. state-size,
- ii) Time to cold-sync,
- iii) Update propagation latency,
- iv) Expected total number of replicas,
- v) Expected replica-set modifications (joins and departures),
- vi) Expected volume of concurrent events.
Canvas & Prolly Tree
Background
Canvas is a runtime for distributed TypeScript applications. It utilizes IPFS stacks to fill the goals, etc, IPLD, LibP2P, Gossip-pub/sub, and logger.
- Core Components:
Major innovation
P2P-optimized Prolly tree, just is used to fast sync between ordered sets of actions. Actually, Prolly looks more like a skip list than a tree:
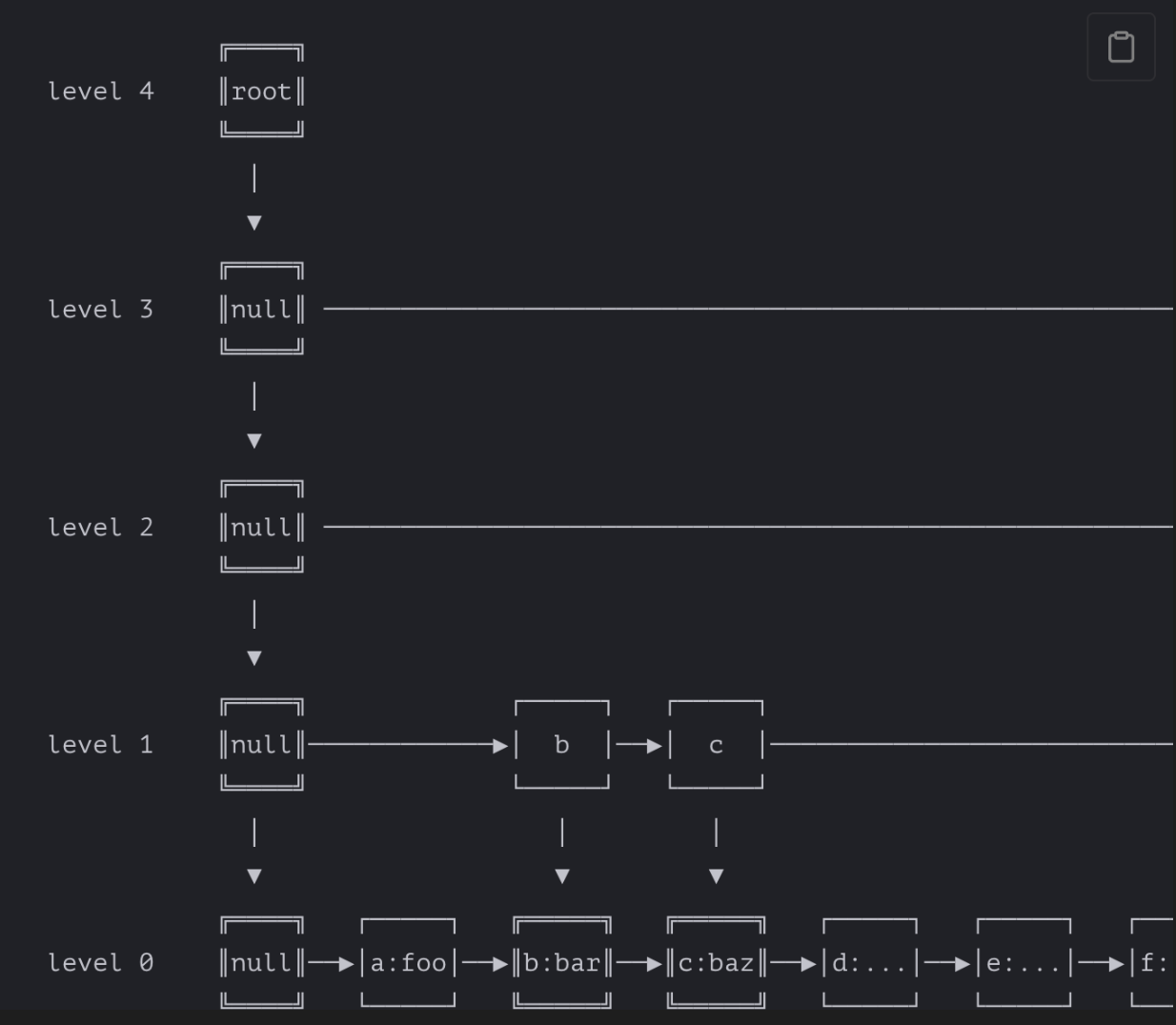
pros and cons
- Pros
- The GossipLog embeds the Lamport clock to a unique message ID to fulfill CRDT.
- Using use the Prolly tree as the KV-DB index to fast sync is the more lightweight way.
- Cons
- Compared with orbitDB, it is relatively new and need more time to battle-scarred.
HLC
Logical Physical Clocks proposes a hybrid logical clock, that combines the best of logical clocks and physical clocks.
HLC captures the causality relationship like logical clocks and enables easy identification of consistent snapshots in distributed systems. It fits into 64-bit NTP timestamp format and embeds physical time to the Logical clock.
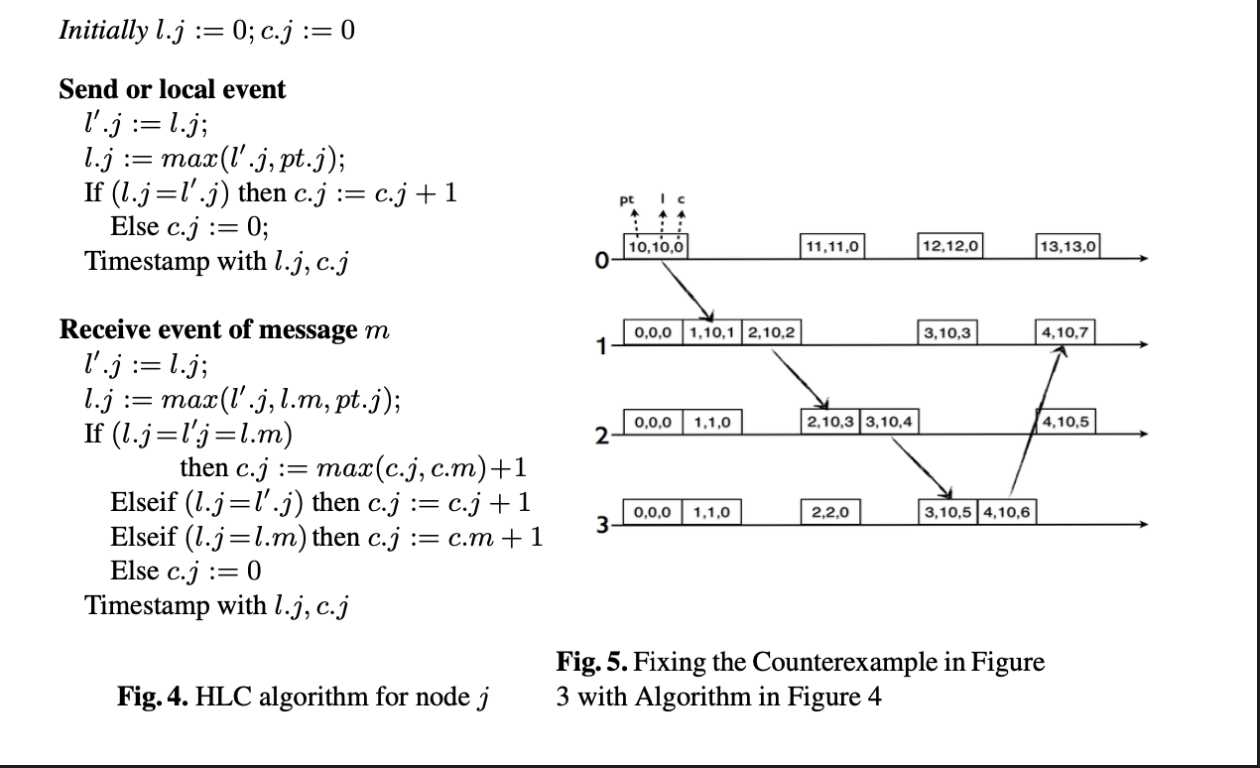
Conclusions
At this stage, we first refer to orbitDB, which implements Merkle-CRDTs, and canvas project, which implements Prolly Tree.
Reference
- Overview
- Core concepts
- Merkle-CRDTs
- Background
- Major innovation
- pros and cons
- Canvas & Prolly Tree
- Background
- Major innovation
- pros and cons
- HLC
- Conclusions
- Reference